


Don’t Trust, Verify ... Your Visual Stats
A few strategies to deal with normalization and aggregation when visualizing summary statistics.

In my last post on the role of data transformation in visualization, I described issues that exist when we visualize summary statistics. In short, summary statistics can hide information and lead to incorrect conclusions if one is unaware that they can mislead. After posting it, some readers correctly noticed that while I gave a useful description of the problem, I did not discuss possible solutions. This post stems from my thinking about addressing problems with misleading summary statistics.
While I originally wanted to provide a solution for every problem I described in the original post, I quickly realized that a better strategy is always to remember to explore different solutions. In fact, there is no simple, foolproof way to address these problems. A better approach is to remember to explore multiple solutions and always verify what one can learn by changing the way the data is transformed and visualized. In other words, the master skill is not to have a ready-made solution for every problem but more to develop the intellectual curiosity and “restlessness” necessary to understand what transformations and visual representations are more appropriate for a given problem.
In light of that, it occurred to me that there are two pairs of data transformations that one should always explore. Each of these transformations can reveal something new and help you avoid fooling yourself. Each pair has a combination of transformations that are one the opposite of the other.
These transformations are:
1. Normalize/Denormalize
2. Aggregate/Disaggregate
Normalize/Denormalize
The first problem I described in my previous post is the base rate bias. I am going to reproduce the problem here. If you show the count or sum of something across different categories, e.g., across geographical areas, the values can be correlated with the frequency of the entities in that area, and you can end up with wrong conclusions. In the image below on the left, you can’t judge how dangerous a given area is by counting the number of people injured because the number of collisions depends on the traffic volume in the area.


A solution to this problem is to “normalize” the values using a sensible denominator. It can be the population size, the number of cars that are present in the area on average, or the number of collisions. Since we have the number of collisions in each area in this data set, I created the map on the right that shows the average number of people injured per collision.
The thing to keep in mind is that every time we visualize counts or sums over some dimensions such as geography, time, categories, etc., we have to verify what happens when we normalize these values to get rid of a potential base distortion.
Since normalization can be applied in many different ways, it is essential to know what type of normalization has been applied. This can be communicated in the legend, in the title, or the caption. It is also important, if possible, to try different types of normalization and be transparent about why one has been used over others, if possible.
Given what I wrote above, one may think that the solution to every problem is always normalizing these numbers. But in many cases, normalization itself can be problematic. The biggest problem with normalization is that once we normalize, we don’t know if the normalization is calculated from a small or large number of elements. When normalizations come from a few elements, extreme numbers are more likely, and more variability is expected. So we can’t just normalize blindly. In particular, very low and very high values are often the results of summaries calculated over a very small number of elements with some extreme values. In the example I gave above, if the number of collisions in a given area is very low, the average number of people injured1 can be very high or very low if the few collisions recorded happen to have a very low or very high number of people injured.
So, what can we do when this happens? Here are four solutions:
Filter out the entities with too few elements (and mention the filtering when communicating the data to others).
Visualize the uncertainty around the calculated values, for example, by calculating and visualizing confidence intervals (interestingly, visualizing uncertainty around values in maps is not very easy - my colleague Michael Correll has a neat solution based on color).
Visualize the frequencies together with the sum and/or the normalized values. This can be done either by creating two versions of the same plots, one for the chosen statistic and one for the frequencies or by using different visual channels to represent the two values. For example, in a bar chart, one can use bar length for the statistics and color intensity for the frequency.
Aggregate/Disaggregate
An orthogonal problem to the problem of normalizing and denormalizing is whether one should aggregate or disaggregate the data. When we have primary data, each observation has associated variables containing values that have been recorded and measured. When we are confronted with the problem of visualizing these data, we are always confronted with the pros and cons of visualizing the individual objects recorded in the data or aggregated objects and their corresponding aggregated values.
Using our running example, while each collision has a specific number of people injured when the collisions are grouped by geographical area or contributing factor, their individual values are substituted with a surrogate value representing the group. This is very useful, but it can also hide important information. For this reason, it is important always to verify what is behind an aggregation. One way to do that is to visualize the individual units instead of their surrogate group values. This can be done, for example, by substituting bar charts with strip plots, choropleth maps with dot maps, and line charts with scatter pots, where one of the axes is time. Take a look at how the map above compares to a version with the same data visualized as a dot map, that is, where each dot is an individual collision, and each dot is scaled and colored according to the number of people injured2.


Now we can see where individual collisions with a high number of people injured happened. Do you see the large, darker dots? Notice that with individual dots, we can also more easily recognize geographical features like roads and highways, as well as Central Park in Manhattan, which is obviously empty.
Of course, every solution brings new problems, so here, as in the case of the normalization/denormalization combination, we have to recognize that disaggregation can also be misleading. The problem with disaggregation is that it often leads to generating a lot of overlapping visual elements, thus potentially hiding relevant patterns and trends. If one is not careful, the resulting image can hide a lot of potentially useful information.
In order to obtain the image above, I made two key choices: I focused only on the collisions that happened in 2021, and I mapped the number of people injured both by color and size. Below, you can see what the map looks like if you map only color or only size and see that neither of them is as expressive as the one I proposed above (which, by the way, can still be improved in several ways).


Comparing the aggregated and disaggregated versions, one can appreciate that they are good at different tasks. The aggregated version is cognitively less taxing, making it easier to identify specific areas that can be labeled and named. The disaggregated version is excellent at showing details and special cases, provided it is designed carefully. In the end, my advice stands: you need to explore both. As I mentioned above this is not specific to maps, the very same effects exist with most visual arrangements where you can substitute aggregations with individual data points and vice-versa.
Given the complementary benefits of aggregated and disaggregated views, one may wonder if there is a way to put the two together, and the answer, in some cases, is yes. One solution I really like when the goal is to show data distributions and averages at the same time is the raincloud plots proposed by Allen et al. Here is an example of raincloud plots taken from the paper.
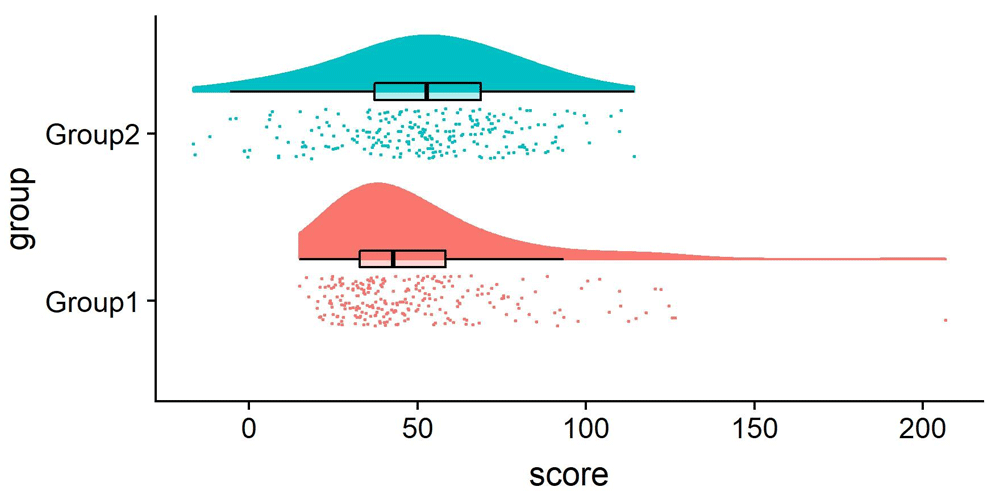
As you can see, for these plots, we get the benefits of both strategies: overall distribution from the top parts and details from the bottom parts.
Conclusion
As you can see, there is no single solution for a given problem. However, I think that keeping in mind these four strategies can help avoid being stuck into specific metrics or solutions. Whenever I perform data analysis, I always explore these four options. I’ll normalize to get rid of base rates, but then I’ll remember that some values may be calculated from low-frequency entities, so I check and try to remove or deal with spurious measures. Similarly, I often switch back and forth between visualizing statistical aggregates and individual data points. If I start from individual data points and realize some potentially interesting trends may be hidden behind the clutter, I try to aggregate to see if I can uncover some useful signals. All these steps have been very useful to me in countless data analysis projects, and I am sure they will be useful to you.
In a previous version of the article, I mistakenly wrote “the average number of collisions.” To make sense, this sentence needs to refer to the number of people injured, which is normalized according to the number of collisions.
I actually had to restrict the data to 2021 collisions to make the patterns visible. I also had to remove collisions with no people injured.