


Reading Club #3: “Visualization Mirages”
Discussing the concept of "visualization mirages."

Last week, we had the third round of the FILWD reading club, a gathering of FILWD subscribers I organized to discuss one or more visualization research papers on a specific topic. Here is a short report of the meeting and reflections on the format and its future after organizing this event for the third time.
The paper
This reading club focused on one specific paper:
McNutt, Andrew, Gordon Kindlmann, and Michael Correll. "Surfacing visualization mirages." Proceedings of the 2020 CHI Conference on human factors in computing systems. 2020.
The concept of visualization mirages is intriguing and useful. Here is how the authors define it:
“A visualization mirage is any visualization where the cursory reading of the visualization would appear to support a particular message arising from the data, but where a closer re-examination of the visualization, backing data, or analytical process would invalidate or cast significant doubt on this support.”
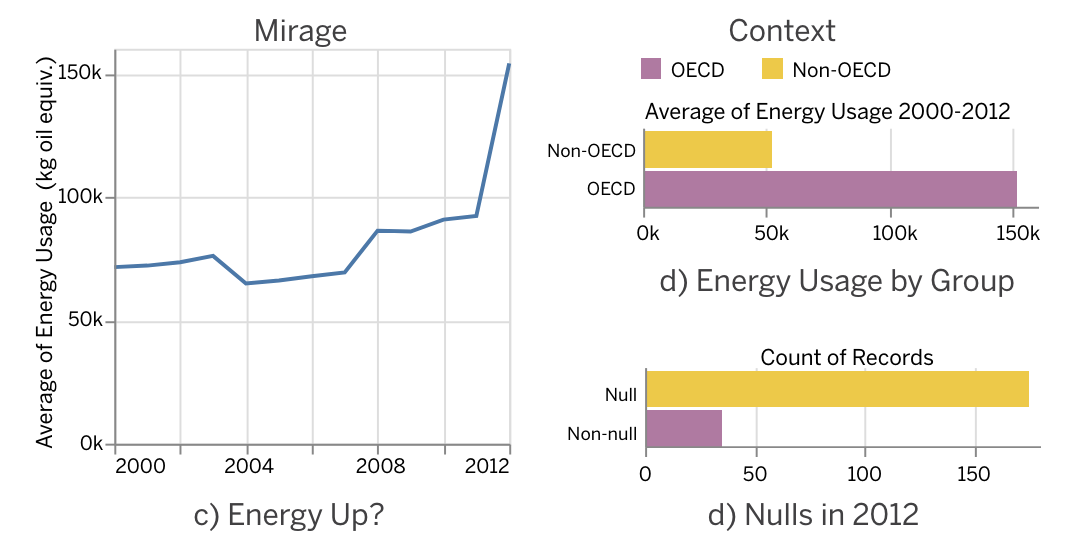
An example from the paper will make the concept easier to grasp. The graph below shows energy consumption over time for the countries in the “World Indicators" dataset.

From the graph on the left, one can infer that energy consumption declined considerably in 2012. However, a closer look at the data reveals that this is just an artifact due to the presence of many null values in 2012 (see the graph on the right) and the use of a sum function to aggregate the values across the countries (see the y-axis in the chart on the left).
Well … this problem is easily solved. It is sufficient to use the average consumption instead of the sum to solve the problem. Energy consumption did not increase in 2012. It decreased! But … upon further inspection, one realizes that this is also a “mirage.” Most null values in the calculation come from non-OECD countries, which have a much smaller energy consumption, thus skewing the average towards a higher energy consumption.
This is just one example among many. The paper does a really good job of describing how mirages can stem from different steps of the visualization pipeline. This is the diagram used in the paper.

Data curation, wrangling, visualization, and reading can cause several problems that eventually show up in how a reader interprets and derives inferences from the data. (As a side note, this model is similar to the one I use in my Rhetorical Data Visualization Course.) In the example above, the problem stems from how the data is transformed (specific types of aggregations), but it shows up in the specific interpretation one derives from it.
The rest of the paper focuses on a series of tests to detect visualization mirages automatically using “metamorphic testing,” a concept developed in software engineering. Metamorphic testing is based on the idea that certain changes in the input should not generate certain relations in the output. For example, shuffling the order of the data points should not change the image generated in the output for some visualization techniques.
Our discussion
In this third reading club we used the same discussion prompts we used in previous reading clubs:
What is exciting about this paper? What do you like about it?
What are the important limitations and challenges?
The only major difference this time was that we focused exclusively on one single paper.
We touched upon many different topics. Here, I’ll provide some highlights.
Stages/process
Many commented on the pipeline presented in the paper. We agreed that having the steps laid out that way with references to what kind of problem they can generate is really useful. One issue that was raised is about what to do when someone does not have control over the whole process. For example, it’s not uncommon not to have an influence on the data generation process, even though many problems can stem from it. At a minimum, one has to have knowledge of how a given data set has been generated and manipulated, starting from the collection of the raw data.
Linting and automation
The paper mentions the idea of “linting,” which refers to recommendations code editors produce to help programmers produce better code. The idea is to borrow the concept of linting and use it for data visualization. Is it possible to produce automated methods that warn data professionals of problems that may exist with their analysis and communication strategy? The concept is attractive. However, one issue that was raised is how to generate and communicate these recommendations without becoming too annoying.
Teaching/learning
We also discussed the teaching and learning aspects of visualization mirages. How can we use this information to teach learners to recognize and avoid these problems? One issue that was raised is: when is the right time to teach these concepts in the development stage (we had a similar discussion in the previous reading club on visualization literacy for children)?
Anecdotally, I introduced some of these concepts to my students in the Rhetorical Data Visualization course I taught last year. I was surprised at how quickly they learned the concepts and could reason about these problems. In any case, I am convinced that we need way more material and courses in this space.
Reflections on the format
This third meeting was probably the one best organized. Scaling down the reading to one paper allowed us to have a slower pace, which relaxed the discussion. Like in previous editions, many people were highly engaged, and we had interesting discussions. By the end of the session, I felt everyone had expressed what they had to say. My post-even feedback confirmed that the participants had a good time and would be happy to participate again.
The Future of the Reading Club?
When I started this experiment, I told myself I had to organize three events before deciding what to do next. Now, I have a good format. I am convinced that reading one single paper is the best way to go, and I know that our conversations are lively and interesting. Now, it’s time to decide what to do next. Here are some steps that I am considering:
Pre-plan many dates in advance. So far, I have run polls to find dates that work best for the people who signed up for my reading club mailing list. This approach takes a long time to organize and is error-prone. A much better approach is to plan a series of reading clubs in advance (probably a whole semester). I will also try to experiment with different times to allow people from different time zones to participate. In our last reading club, we had a person participating at 3 am!
Scale up. So far, the reading club has been advertised to a small group of people. Little by little, I’d like to find a way to make it bigger. But the problem is that it’s not possible to have a meaningful conversation with a hundred people, so I have to find a good balance. One related problem I found is that some people sign up but don’t show up the day of the meeting and this is something I’ll have to take into account.
Simplify and automate. Even though I did not talk much about it, organizing a reading club requires a lot of steps, and I can’t be in charge of everything. The only way to make it a viable project is to simplify and automate as much as possible. The first simplification is the one I mentioned above: I’ll just set dates and times for a series of reading clubs in advance. I will also find ways to automate the emails I must send before and after meetings.
If you want to join a future reading club, add a comment below. If you are a FILWD subscriber, you will hear from me during the summer. Once I have the system I mentioned above in place, I will send an announcement to all FILWD subscribers and allow everyone to join the reading club's mailing list.
I would be interested in joining a future reading club session. Thanks for the informative writeup and pre-testing the format.
I come with a less technical background than most but I am iintereste din teh dicscussions and would like to join future reading club sessions.