


VisML#2: Who Needs Visualization in Machine Learning? To Do What?
Post #2 of the series on Visualization for Machine Learning. We introduce different roles and their goals.

Data visualization can support many different types of stakeholders. Identifying these types is crucial in designing appropriate visualization systems because their needs and tasks vary considerably. The research literature offers many different categorizations. Here, I’ll partially borrow and then expand on a paper I published with my co-authors in 2018 (one of my recent favorites!):
Human Factors in Model Interpretability: Industry Practices, Challenges, and Needs. Sungsoo Ray Hong, Jessica Hullman, Enrico Bertini. Proc. of the ACM Conference on Computer Supported Cooperative Work (CSCW), 2020.
The paper is an interview study on ML Interpretability aimed at understanding current practices and needs in the industry. In that study, we categorized users into three main classes: model makers, model breakers, and model users. These roles are a good starting point for our analysis, even though, as you will see in a moment, I will need to add more to create a complete picture of who may benefit from visualizing machine learning.
Roles
These are the relevant roles identified in the paper, plus some important ones to recognize and consider.
Model makers (developers)
The people who build ML models and solutions (you can also call them developers, data scientists, or the fancier MLOps). Within this class, I used to group ML researchers, but I now think researchers need a separate class. Researchers tend to focus more on developing new methods. Developers tend to focus more on developing solutions with existing methods and verifying that the solution works for their target application. Of course, this distinction is, in practice, not as neat, but to understand how visualization supports ML development, this distinction is essential.
Model breakers
Those who verify that the model works as intended. This category includes a wide variety of people, including some model makers. However, it typically includes product managers, risk officers (especially in highly regulated markets), and model adopters who must verify that things work as expected before an AI solution is integrated into an organization. The role of risk officer is discussed less in the literature but is extremely important and in strong need of support. Companies in regulated markets like banking have specialized personnel to ensure that models behave as expected and comply with regulations. The fact that developers and evaluators are not on the same team is crucial to ensure undesired biases and influences. The Model Risk Managers’ International Association (MRMIA) has an interesting technical report describing the role of ML risk officers.
Model consumers (users)
These are domain experts or laypeople who use the developed ML models to carry out tasks in their environment to achieve their goals. Here, we have healthcare professionals, business experts, HR teams, etc., who use ML/AI systems to make decisions in their environment. This category also includes the important subcategory of scientists who use ML to explore scientific phenomena through various types of ML modeling. Model consumers are way less defined in the current literature; this is where I see an important gap. In any case, my intuition is that visualizations here could help with two high-level goals: onboarding and interpretation. In onboarding, model users explore the model decision space to understand how it behaves and generate a mental model. In interpretation, visualization can play a major role in putting model output in context so that users can integrate knowledge from the model more meaningfully.
Model explainers
This class did not exist in our original paper, but I am now convinced it is an important group of people to consider. Explainers are educators, researchers, and enthusiasts interested in using visualization to describe how ML works to other people. This is where people develop “explanatory visualization,” which walks the readers through several steps to help them develop an intuition and understanding of how some ML technique works. The Financial Times, for example, published this fantastic explainer on Large Language Models not too long ago.
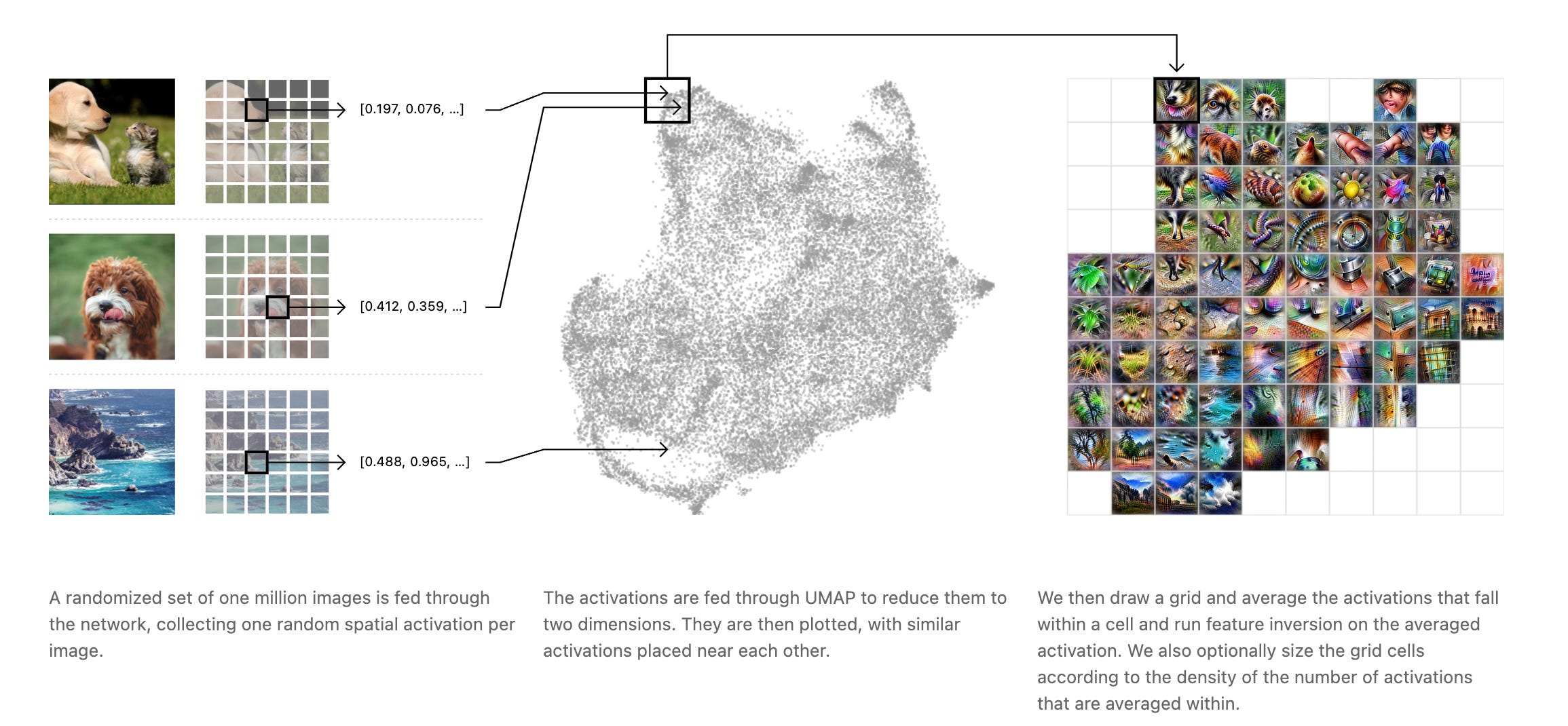
And if you want to blow your mind you should definitely take a look at the incredible, but now discontinued, distill.pub, an online magazine/journal that focused on ML visualizations and started when nobody was talking about AI and ML yet, except the experts at work (their first explainer was published in 2016 🤯). If you have never heard or it, do yourself a favor and check the amazing articles they published over the years. Take a look at the “Activation Atlas” if you want to start somewhere.
Finally, if you want a taste of the efforts of academic visualization community in this space, take a look at the Workshop on Visualization for AI Eplainability, which is at its 7th edition already, and you’ll find even more amazing examples.
Model researchers
As I mentioned above I think ML researchers deserve a separate category. Researchers are ML experts who develop new ML methods and techniques—the cutting-edge. While developers are more into using existing methods to solve specific applied problems, researchers are more into developing new capabilities and methods. When I mention researchers, one should not equate this to academic researchers because a lot of innovation in ML today is happening in companies. However, what ML researchers have in common is that their goal is to develop new capabilities for ML and AI, and as such, they have a stronger focus on understanding how models do what they do rather than what they do. For this reason, this is the main class of users who have some interest in looking inside models to understand what specific components or parts of the architecture do. While the academic community has developed many of such visualizations, I have a hunch that looking inside models is something that interests almost exclusively model researchers (and this is, of course, not to say that because of that, they are not important).
I want to conclude this part by clarifying that an individual can cover many of these roles at once and that this is a very coarse categorization. However, despite its limitations, this categorization is helpful to reason about what goals and tasks exist in ML visualization and how we could provide support to these roles.
Goals
In the following, I cover a few common goals that can be supported by data visualization. This list, like the roles outlined above, is by no means exhaustive, but I think it can help us reason about what visualization can do in this space.
Improve model performance
Model makers are, above all, interested in building models that make as few mistakes as possible and have high accuracy (“What is the model performance?”). But this is not the only criterion possible. Model makers also want to see what kind of errors the model makes because some errors are more problematic or riskier than others, a goal they partially share with model breakers. So even if two models have similar performance, one may still prefer a model that makes certain kinds of errors or errors that are more manageable than others (“Where and when does the model make mistakes? Where do the mistakes come from? How can we build a better model?”) Relatedly, model makers often want to check if the model “generalizes” well, that is, whether it’s going to behave as expected with data the model will receive in the future, once it’s in production. While some statistical methods exist to deal with generalizability, manual inspection as a sanity check is also important (“How does the model behave with instances I know might be problematic? In what areas of the input space is the model more uncertain?”) There is no substitute for looking at specific instances where the model makes mistakes. It is not rare for model makers and breakers to have a library of problematic or hard cases they keep testing when assessing a new model. In future posts, we will cover visualization methods that guide users in detecting and interpreting problematic instances, for example, by arranging instances according to their model score to detect areas where the model may be more uncertain or according to subsets analysts want to inspect.
Compare models
Working with people from industry, I have learned that comparing models is a much more frequent and relevant task than one may initially think. This recent paper, “Operationalizing machine learning: An interview study” explains how pervasive and relevant model comparison is. Model makers and breakers continuously maintain multiple models they compare for various purposes: to compare different modeling strategies, to compare new models with legacy models or models they have in production, and to perform A/B testing with models they deployed. Risk officers often develop “challenger models” (Deloitte has a nice report on them if you want to learn more about the topic) to compare with models they receive from the development team. So, as you can see, model comparison is everywhere.
This is interesting because comparison is a key research area in visualization. Visualization is extremely powerful in helping people compare objects or entities. Still, the design space of comparisons is often large, and one needs to understand how visual comparison works to make it effective. In this space, my friend Prof. Michael Gleicher is a real expert. If you are unfamiliar with his work, I strongly recommend this classic paper, “Visual Comparison for Information Visualization.”
Unfortunately, and surprisingly, model comparison is not well supported by existing visual analytics tools and it has not been identified as a fundamental task (“How do the models compare? How do they differ in terms of decisions and errors they make? Why do they differ?”) The image below shows an example of model comparison technique from Model Tracker, a tool developed by Microsoft Research and presented in this paper in 2015 (!), “ModelTracker: Redesigning Performance Analysis Tools for Machine Learning.” The little squares are individual instances, and the horizontal axis represents the model score. The lines and arrows you see represent changes between two different versions of the model.

Assess risk
Once models are developed, it is essential to have people check what risks they carry. In many settings, this role can be covered by a project manager responsible for the product or, in regulated markets, by model risk officers. In many situations, model evaluators must be different from model builders because they do not have any specific attachment or stake in the model's performance. They succeed when they find problems that builders cannot detect or anticipate. Model breakers typically ask questions about potential points of failure. For example, they may ask, “Can we trust this model? Does its logic make sense? Where could the model fail? What are specific cases where the model should never fail? Where could the model fail unexpectedly? Does the model have relevant biases? Does it comply with regulations?” Although the techniques model breakers and model builders use may end up being similar, their focus is different. Model builders test models to generate insights about how to improve them, while model breakers test models to assess where, when, and how they may fail.
Internalize model logic and calibrate trust
While many models are used to automate tasks, there are many situations where models help people carry out some tasks. For example, models can recommend specific courses of action (e.g., buy or wait?), flag entities/objects to review (e.g., equipment to maintain because it may break soon or anomalies to review in a security setting), rank items (e.g., which business franchises one needs to review to avoid future problems). Sometimes, some of these tasks influence very sensitive decisions, so the stakes are high. Common ones known in the literature are recidivism predictions, ranking people for job hiring, ranking people to decide who to call to prevent hospital readmission, predictions of adverse health outcomes, and many more. The stakes are high! Because of that, the visual interfaces we build to support these tasks downstream (and maybe even upstream) model output are very important.
This is where research is not very well developed yet, and we need to accumulate more knowledge. In any case, the type of questions model users pose are quite different from the ones model makers and breakers have. Users want to understand how much they can trust the output and what they can do with it. In turn, this also means that visual interfaces in this space need people to help with how much uncertainty there is in a recommendation and what the logic that drives a given output is. Common questions users may have include: “Can I trust this recommendation? Does the recommendation make sense? Why does the model provide this recommendation? How uncertain is the model on this prediction?”
Model user tasks may exist globally or locally. At a local level, users are interested in assessing individual cases/decisions they are confronted with. At a global level, they need to understand how the model works in general (i.e., its logic), whether they can trust it, and what specific predictions may be more problematic. Local-level tasks pertain more to the actions and decisions users have to make. Global-level tasks may be part of an initial onboarding and setup phase to help users understand how a model works and internalize its logic.
Understand how models do what they do
Machine learning models are so complex that even their developers are not sure how they do what they do. This is especially true for generative AI, where researchers try to understand how certain surprising capabilities emerge from their structures. In this space, models are studied almost like the way physical phenomena are studied in natural sciences: look at how they behave and what roles individual components seem to have and build explanations and theories around them. Visualization could play a major role here. In the same way, microscopes are used to understand microorganisms and telescopes to understand the cosmos, and visualization, in a way, could be used to understand machine learning models. The articles I mentioned from distill.pub are a lot like that. The authors look at visualizations to develop intuitions about how models do what they do and I hope there will be more works like these ones.
Of course, there is way more than what I captured in the paragraphs above, but my hope is that these can be a source of inspiration to look more closely at how visualization could help in this space.
Why use visualization?
After reading about roles and goals, a legitimate question is: Why use visualization? When and why does visualization play a role in achieving these goals? It’s hard to give an exhaustive answer. In fact, part of the research we will need to do is to have more and more specific answers to this question. But let me try to sketch something here. The way I like to think about this problem is that data visualization can help us develop an understanding (or at least intuitions) about three main aspects of ML models:
Behavior: How does the model behave?
Logic: What logic governs this model?
Mechanics: How does the model do what it does?
Visualization of data coming (or derived) from models and their components can help us draw inferences about these three elements and this is where its real value lies. In future posts I will come back to this idea. In particular, I will focus on data visualizations that focus on specific types of data one can derive from models and how this information helps us draw specific kinds of inferences and intuitions.
Conclusion
That’s all I have to say for now regarding roles and goals. There are aspects of this problem that I am still struggling with, but I am confident the picture will become clearer as this series develops. If you have any ideas or comments to share please leave a comment below. This is very much a work in progress, and I need your help to think these things through! Do you find this helpful? Does it help organize more clearly ideas about how visualization plays a role in this space? Please let me know!
This article reminds me a lot of playing around the the tensor flow playground, when I first start learning about neural networks. Although it could use a little more explanatory umphf.
I am really curious and excited to see where this serious goes. Especially with a line like "observing them in the wild." I love to understand how ambiguous system work and make that information accessible, to help build trust and understanding