
Shape the Data, Shape the Thinking #3: Data Filtering and its Visual Effects
Exploring the effect of data filtering on data visualization.

(This is the third part of my series on data transformation. So far, we covered the role of selection and aggregation and the role of statistical summaries. Here, we focus on filtering.)
Often, in data analysis and communication, we need to reduce information in order to gain clarity. There are two main ways in which we can reduce information: one is to filter out information that is not useful for the task at hand, and the other is to aggregate information into abstractions. We touched upon some abstractions earlier when we looked at aggregate statistics, and we will take a look at abstraction again in the next post on granularity. In this post, we focus on “data filtering.”
What is data filtering? It’s the systematic removal of data objects and data values from a data set with the purpose of focusing on data subsets. Filtering is the tool that enables us to make focusing possible. Focusing is essential because often, in a given data set, there are elements that are spurious and do not add anything other than noise. Sometimes, we also just want to focus on some specific subsets for reasons that pertain to our analysis or communicative intent.
Using our usual NYC collisions data set (see my other posts in the series if you just landed here - this is the data set I use throughout the series), we can find many examples where filtering is desirable. For example, the collisions data set has many collisions with location coordinates that are outside the NYC area. These are probably just errors in the data or, in any case, irrelevant for the purpose of analyzing NYC data. Similarly, if I am only interested in analyzing data from last year, I can safely remove all the previous years from the analysis.
Of course, when we remove information, we need to be careful because we run the risk of fooling ourselves or misleading if we are not careful. As with many of the other choices we have seen in the other posts on data transformation, doing things “right” is really a balancing act, and there is no foolproof strategy one can apply blindly. For this reason, it’s important to be mindful of how filtering impacts visual representations and, as a consequence, how it impacts interpretation.
Ways to filter data
There are many ways in which we filter out data objects in a data set. Some of the most common are:
By value: Keeping only the elements that satisfy a filtering condition (e.g., only the collisions that happened last year). In its simplest form, filtering conditions involve value ranges for any ordered or quantitative attribute and sets of values for categorical values (e.g., only collisions related to substance abuse).
By ranking: Keeping the top-K elements of a list ordered according to some criterion.
Manually: Removing elements manually. Typically, some outliers or some categories are not relevant.
Whenever we filter data, we can expect our visualizations to change somehow. At the very least, if filtering removes data objects, it may lead to removing graphical objects from a visualization. Interestingly, the association between data filtering and visualization change is rarely discussed, yet it is a very important one. Knowing how filtering affects visual representation other than the data is essential to understanding its role and usefulness as well as its potential dangers.
Effects on visualizations
When we filter data, visualizations can change in many different ways. Here, we list and briefly discuss some of the most common ones.
Object removal. The most obvious consequence of filtering is that some graphical objects (bars, dots, regions, etc.) are removed from the visualization. That’s what filtering is about. In the image below, you see all 2021 collisions. The one on the right is only collisions due to following too closely (interesting to see them mostly in the main arteries!).


Overplotting. Another consequence of filtering that is highly tied to object removal is overplotting reduction. If the visualization allows overplotting symbols, like in the maps above, filtering can reduce clutter and make certain trends more apparent. This is what we see on the map on the right, where collisions on specific roads are more evident. Sometimes, when there are too many overlapping elements in a visualization, and we want to reduce clutter without focusing on specific data elements, random sampling is a quick solution that works really well. Random sampling is, in fact, another form of data filtering that, at times, can become very useful.
Rescaling. When filtering is applied to data attributes that are mapped to spatial elements of a visualization (e.g., geographical coordinates of a map or the axes of a plot), large parts of the visualization become “empty,” and rescaling is possible. Take a look at this pair of scatter plots. Each dot represents a zip code, and the two axes represent the average number of persons injured and the average number of persons killed. I created the plot on the right by removing the outliers that you see at the top left and bottom right of the plot on the left. As you can see, the consequence of doing that is to have the two axes “rescale,” focusing on a narrower range than the plot on the left. Compare the maximum values of the two axes in the two plots.


This is a very specific example, but the same logic applies to all plots. When objects are removed, the axes or other mappings that exist between the data and the visual properties of a visualization can be rescaled.
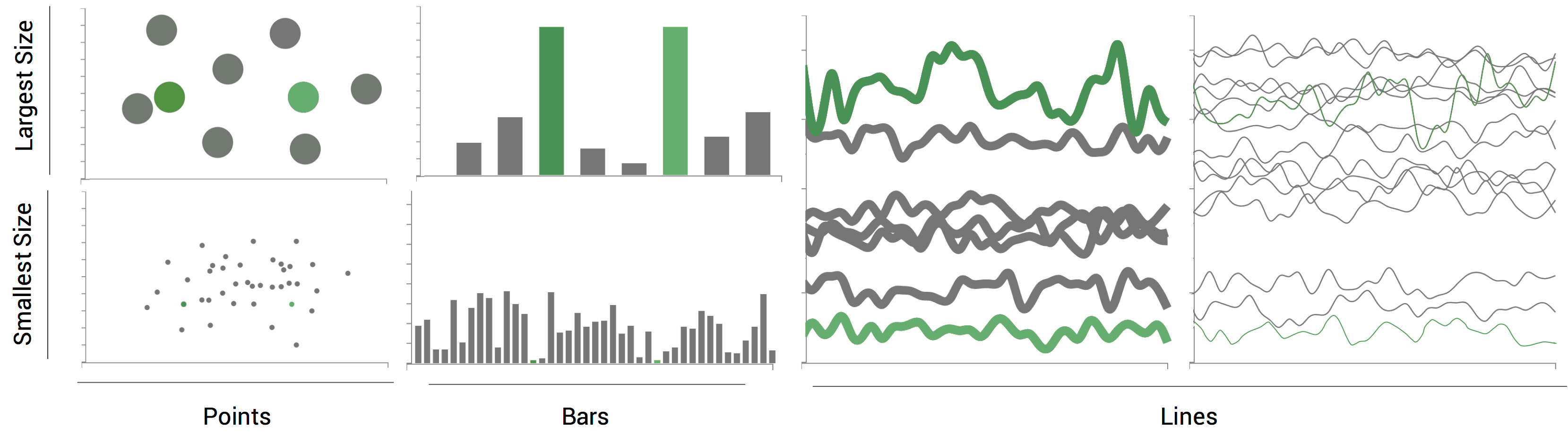
Resizing. Another possible consequence of object removal, similar to what we described above with rescaling, is the possibility of changing the size of the symbols used in the visualization. When more space is available, the retained objects can be resized and, consequently, increase their visibility. Visibility is important for many reasons. An important one is that comparing visual properties such as color becomes easier when the objects increase in size. Prof. Danielle Szafir has a great paper studying factors that affect color perception in visualization. This image from her work shows the effect of size. It’s pretty striking.
Level of detail. Finally, if there is more space and symbols can grow in size, they can also present more details. As we just discussed above, seeing more details can help in data interpretation. A special case of change of details is “semantic zooming.” A semantic zoom is a special kind of zoom where the graphical representation changes in the type of information it shows other than the level of detail. A good example of this effect is the way Google Maps works. Try to zoom in on an area, and you’ll see that more details become apparent as more space is available for areas that were smaller before zooming in. The image below shows the effect when I zoom into the area around Northeastern University. If you compare the image on the right to the one on the left, you’ll notice that the objects on the right are not only scaled, but there is also additional information that is not present in the map on the left. For example, there are several additional labels and symbols.


In fact, zooming is just another type of filtering if you think about it. When you zoom into an area on a map, you are restricting the spatial coordinates of the map. Similarly, when you zoom into an area of a scatter plot, you are performing a filtering operation on the x-axis and y-axis simultaneously.
Value change. Not all filtering operations remove visual objects. Filtering can also just change the values of the quantities mapped to the graphical objects. An example here will make this idea easier to grasp. The two line charts below depict the average number of people injured in collisions by the hour of the day. The one on the left shows the Bronx, and the one on the right shows Manhattan.


If a visualization maps quantities that come from some statistical aggregation, when we filter data values, the statistical aggregations can also change, thus leading the visualization values to change. In other words, some filtering operations can lead only to value change without any object removal, rescaling, resizing, etc.
It’s especially important to be careful with this type of filtering. As you may have noticed above, if one is not explicit in explaining what particular filtering is applied to a given data set, there is nothing in the visual representation that suggests what type of filtering has been applied to the data. Even more insidious is the fact that every time we focus on something, we lose the context of how the same trend looks under different parameters. This is something that can mislead both the analyst during data analysis and readers when these patterns are communicated.
Trade-offs
Above, we provided a list of ways in which visualizations are affected by data filtering. You may have noticed that these operations have potentially positive and negative effects. In general, the positive effects pertain to the need to gain clarity. Filtering helps gain clarity by focusing and removing irrelevant information for the task at hand.
Removing information, however, has some potential downsides. Whenever we focus on something, we lose context and context is important to interpret information. Filtering can also be arbitrary and manipulated in ways that make data look the way one wants. When we communicate data to others, we can, in principle, apply many filtering operations without ever revealing what we have done. The same is true when we use visualization for analysis. We have to make sure we do not fool ourselves while filtering data and remain mindful of the fact that what we observe is conditioned by what we remove.
A thorough analysis of the many ways filtering can mislead is beyond the scope of this post. However, before concluding, I will mention two classic problems that can stem from filtering: cherry-picking and restricted range. Cherry-picking is the problem of keeping only the objects that show the trend we want in the visualization and removing any inconvenient data that contradicts our hypothesis.
Restricted range effects stem from correlations calculated over a shorter range than the whole population, leading to a false sense of low or high correlation that exists only in the conveniently selected range.
There is way more to explore regarding the cognitive effects of filtering, but for now, I just want to give a clear way to think about the role of filtering in visualization. Filtering is powerful and necessary, but at the same time, it must be used with extreme care.
Post a comment to let me know what you think. Did you find this post useful? Do you have some personal experience with filtering you’d like to share? Did I miss anything? Is there anything I can clarify further?
If you liked this post, please help me spread the word about the work I am doing here. The more people we are, the more we can learn from each other! Thanks!!! 🙏