
Shape the Data, Shape the Thinking #1: Selection and Aggregation
Selection and aggregation give shape to the data. Shape implies the type of questions we can ask and messages we can send. They also affect what visual representations are available and appropriate.

(This is post #1 for the series Shape the Data, Shape the Thinking on the role of data transformation in data visualization. In this post, I’ll focus on the role of variable selection and aggregation.)
Ah! Selection and aggregation. The mighty combo of data transformation. What are they, and why are they so important? To explain, I will use the NYC Vehicle Collisions data set as a running example (a classic data set I have been using for years in my visualization courses). The data set contains vehicle collisions in New York City. Each row represents one collision, and each column represents one attribute (variable) describing the properties of the collision. This is a version of the original data table with a reduced set of variables. The original one has a total of 29 columns describing many aspects of the collisions I do not cover here.

Now … if I want to create a chart out of this dataset, I have to make two choices: select which variables (columns) to use to build my chart and, optionally, aggregate the data objects according to one or more of the variables I selected. Let me describe each in turn, together with an analysis of the implications of these choices.
Selection as Relationships of Focus
Imagine I am analyzing this data set, and I want to pursue this question,
“How did the number of people injured evolve over time?”
To pursue this question, I need to select two variables: date and number of people injured.
If I want to study a different question,
“How does the number of people injured distribute across the city (at the level of zip codes)?”
I need to select the zip code and number of people injured.
So, different questions require the selection of different combinations of variables. But different combinations of variables produce different “data shapes,” i.e., relationships, comparisons, and trends. And different “data shapes” enable different types of questions and messages one can pursue (and, of course, different data representations).
One way I like to think about this problem is that every visualization is, at its core, a combination of a series of discrete variables and one or more quantities (often one or a maximum of two quantities). The most basic combinations include combinations of nominal values/categories, ordinal values/sequences, times/dates, locations/regions, and one or more quantities.
Of course, there are more complicated combinations than these ones, but these tend to be the bedrock of what one mostly sees around. Also, more complex combinations tend to be more sophisticated elaborations of the ones above (with some exceptions I prefer not to cover here for simplicity).
If I have a nominal attribute and a quantity, I will compare quantities across the categories. If I have time and a quantity, I will observe the temporal evolution of the quantity. If I have geographical areas and a quantity, I will compare the geographical areas and assess the spatial distribution of the quantity over the geography.
This, in turn, means that when a visualization does not clearly show what is needed, often the main culprit is not the visual representation chosen to represent the data but the specific data shape developed to communicate the idea one has in mind. It can’t be overstated how important and neglected this fact is in the general discourse around data visualization.
So, the most basic data transformation is about selecting the “right” combination of variables for the specific analytical or communicative intent one has.
Aggregation as Objects of Focus
The second step, which is optional but often needed, is aggregation. The two questions outlined earlier can’t be answered without an aggregation step: we need to aggregate all the individual collisions in the same month for the first question and all those in the same zip code for the second one.
Here is an illustration of how this works.
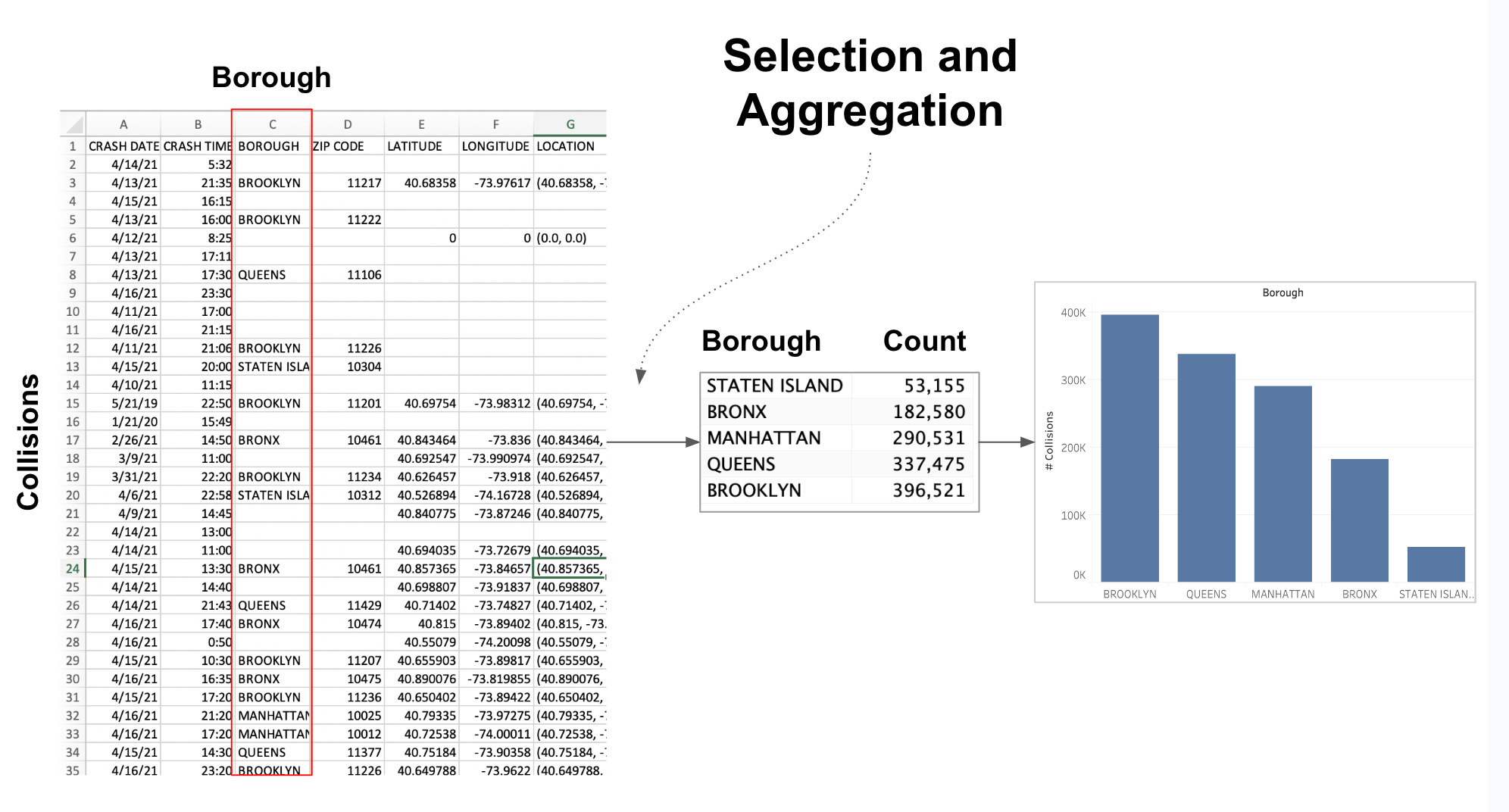
If I want to compare the boroughs according to the number of collisions taking place in them, I first have to aggregate all the rows that refer to the same borough and count how many rows (i.e., collisions) there are in each one.
A useful way to look at this problem is that the existing data table one receives as an input needs to be transformed into a new table that contains all and only the information that is needed to build your chart. Typically, one where every row corresponds to one graphical element in the visualization (it’s not always like that, but it’s a useful abstraction). You can see an illustration of this idea in the image above, where the original data table is transformed into a smaller one containing the information that is eventually mapped to the bar chat.
For this reason, when I think about the role of aggregation in visualization, I think about what objects are the focus of the visualization. To make this more clear, if I aggregate by zip code, the visualization will compare data values across zip codes; that is, the zip codes will be my objects of focus. Similarly, if I aggregate by vehicle type, my objects of focus will be the type of vehicles.
This kind of reasoning is often implicit, but it’s very helpful when we create visualizations for analysis or communication to explicitly think, “What are the objects that I am visualizing?” This gives us a better sense of the type of comparisons we are enabling. Aggregations imply objects of focus, and objects of focus imply comparison.
Selection as Quantities of Focus
While the primary role of selection is to produce the right data shape to focus on certain types of relationships, selection also produces the quantities of focus. As I mentioned above, most visualizations are combinations of discrete values and one or more quantities. But often, in a data set, there are alternative quantities one can use or compute. For example, in the collision data set, one can count the collisions or use the number of people insured, the number of people killed, the number of pedestrians injured, the number of pedestrians killed, etc. Selecting one of these variables over another clearly has important implications, so deciding on specific quantities to use is also a crucial aspect of data transformation.
Impact on Visual Representations
So far, I have barely mentioned the visual representation part of these transformations. I have omitted this information on purpose to emphasize the idea that selection and aggregation strongly influence what will be visualized and, as such, what relationships and objects will be the focus of a visualization even before one decides what visual representation to use.
That said, it’s important to be mindful of the effect of these transformations on visual representation.
The type of variables that are selected largely imply what type of visual representations will be available and appropriate. For example, with geographical data, maps are an option that is not available with other combinations; with temporal or ordinal data, line charts are an option that is not appropriate for nominal data (since it would imply an order that does not exist); with two quantities, scatter plots are an option that is not suitable for combinations of discrete values (since many data points would fall in the same discrete positions).
Aggregation determines how many objects will be presented on the visualization and what these objects represent. Typically, one element in the data table corresponds to one element in the visualization, so the type of aggregation one uses has an impact on the number of visual markers (symbols) and, more importantly, their meaning.
Conclusion
Selection and aggregation determine the shape of the data, and the shape of the data determines the focus of our analysis and the messages we communicate. Selection implies relationships and quantities of focus. Aggregation determines what type of object will be mapped to the visual symbols that constitute a visualization and, in many cases, how many of these objects will be represented. Being mindful of the role of these important operations makes it easier to understand how these choices have an impact on visualization even before one chooses what specific type of visual representation one wants to choose.
—
Hey, if you found this post useful/insightful. Would you mind leaving a comment below to let me know your opinion/ideas about it? Did I miss anything? Is there something here you found particularly insightful or maybe confusing? How will you use this information in your work?
My goal is to turn this series into something more permanent (book, video lectures, etc.), so your opinion matters a lot to me.
Thanks!